En esta primera entrega de la serie en la que hablaremos sobre cómo gestionamos la calidad en Powens Group, nos centraremos en nuestro sistema de priorización de anomalías.
Érase una vez… los bugs
Casi cualquier ingeniero estará de acuerdo en que no existe el software perfecto. Los bugs (errores de software) existen y siempre estarán ahí. El software es un sistema complejo y cuanto más complejo es un sistema, más probable es que falle.
Claro que se puede optar por una política de tolerancia “zero bugs”. Es decir, no lanzar nada nuevo hasta haber corregido absolutamente todos los fallos conocidos, incluso los menores. Esto puede funcionar si el software no es muy complejo o depende poco de servicios externos (es decir, si la mayoría de los errores vienen de dentro y no de terceros).
Pero desde un punto de vista empresarial esta estrategia puede salir cara. Como en otras industrias que requieren inversión previa antes de ser rentables, el software tiende al monopolio, sobre todo si hay efectos de red. Hoy, unas pocas tecnológicas concentran el 30 % del valor del S&P. A diferencia de sectores tradicionales como el petróleo, el gas o la biofarmacia, el software tiene barreras de entrada más bajas, pero una velocidad de innovación altísima. Esto significa que un equipo pequeño pero talentoso puede convertirse rápidamente en un competidor serio, sobre todo si el producto está muy comoditizado. Para seguir liderando, hay que invertir de forma constante en innovación y nuevas funciones.
Y aquí entra en juego el Open Banking, que cumple todos los requisitos anteriores: depende de servicios externos (APIs o webs de bancos), es altamente competitivo y sus productos no varían mucho entre proveedores. Los efectos de red y la escala lo son todo: los clientes eligen a quien más bancos conecta. Y, como guinda, las APIs y webs bancarias no destacan precisamente por su estabilidad.
Con todo esto, lo lógico sería pensar que la banca abierta tiene una tasa de errores mayor que otros sectores del software. Pero, como veremos, en nuestro caso no es así.
¿Qué significa esto para Powens Group?
Primero, un apunte sobre terminología: evitamos hablar de bugs, porque la gran mayoría de nuestras incidencias no son fallos propios, sino que provienen de factores externos que no controlamos.
Dicho esto, vamos a los datos. En Powens Group mantenemos 5 millones de conexiones bancarias activas* entre Europa y Latinoamérica, y cada mes añadimos entre 50.000 y 100.000 nuevas. Nuestro sistema de monitorización detecta unas 30.000 anomalías al mes (desde una cuenta individual que no se actualiza hasta un banco entero que deja de estar disponible para ciertos usuarios). Esto nos da una tasa de error del 0,6 % y, por tanto, un 99,4 % de éxito. Nada malo para un sistema que depende de más de 1.800 fuentes externas.
Si agrupamos esas anomalías por origen, nos quedan unos 500 problemas únicos al mes. Esto equivale a unos 1,2 errores por KLOC (cada 1.000 líneas de código), un estándar de calidad comparable al de los mejores sistemas empresariales. Así que, objetivamente, nuestro nivel de calidad es alto. Y teniendo en cuenta que la mayoría de las incidencias vienen del exterior, podríamos decir que es excelente. Pero los clientes no piensan en términos absolutos y hacen bien.
Desde una perspectiva relativa, el panorama cambia. Nuestro equipo de mantenimiento puede resolver unas 100 anomalías al mes. Eso deja 400 sin solucionar, lo que implica que solo corregimos un 20 % de los problemas detectados.
*Una conexión bancaria representa un enlace de datos específico entre un usuario final (una persona física o jurídica) y su banco. Una sola conexión bancaria puede dar acceso a varias cuentas si el usuario tiene más de una en ese banco en particular.
Entonces, ¿cómo actuamos?
- Una opción sería dedicar más desarrolladores al mantenimiento de conectores, pero eso frenaría mejoras clave en infraestructura, bases de datos, seguridad o nuevas funciones.
- Otra opción sería reducir el número de conectores bancarios que ofrecemos. Menos conectores, menos errores. Pero eso también significaría menos conexiones exitosas y menos ingresos.
- Y la tercera opción es centrarse en resolver primero las anomalías más relevantes: las que afectan a más usuarios o impactan más en la experiencia, aunque eso implique priorizar de forma diferente a como lo harían algunos clientes.
¿Con cuál te quedarías?
Nuestro sistema de priorización
Spoiler: elegimos las tres. El año pasado lanzamos un sistema de resolución de anomalías que combina estas tres estrategias en un enfoque único. Se basa en tres principios: (1) alinear expectativas con la realidad, (2) centrarse en el impacto y (3) gestionar el caos.
Alinear expectativas con la realidad
Ser realistas significa saber qué podemos hacer y qué no, y explicárselo claramente a nuestros clientes. Ellos tienen que entender por qué tomamos ciertas decisiones, sobre todo las más difíciles.
Empezamos por analizar todos nuestros conectores y aceptar una realidad: no todos son igual de importantes. Los bancos grandes concentran la mayor parte del uso. Otros, como bancos pequeños o nuevas plataformas, son más de nicho.
También hay conectores que requieren más trabajo, ya sea porque su API es inestable o porque su web cambia con frecuencia. Y algunos, aunque no se usen mucho o generen muchos problemas, son clave para nuestro crecimiento (por ejemplo, al abrir un nuevo mercado).
Para reflejar todo esto, creamos un sistema de niveles:
- Tier A para conectores muy importantes
- Tier B para conectores importantes
- Tier C para conectores menos relevantes
La fórmula que usamos para asignar un Tier (nivel) a cada uno de nuestros más de 1.800 conectores es el resultado de multiplicar tres factores: uso × esfuerzo de mantenimiento × importancia estratégica.
Después, asignamos objetivos de calidad realistas a cada nivel. Usamos como métrica principal la tasa de éxito al conectar nuevas cuentas. Nos comprometemos con objetivos concretos para los Tiers A y B. Los C se atienden cuando los otros dos están cubiertos.
Sabemos que a algunos clientes les cuesta aceptar que ciertos conectores no reciben la misma atención, pero preferimos ser claros. Además, más del 90 % de nuestras conexiones pasan por conectores A.
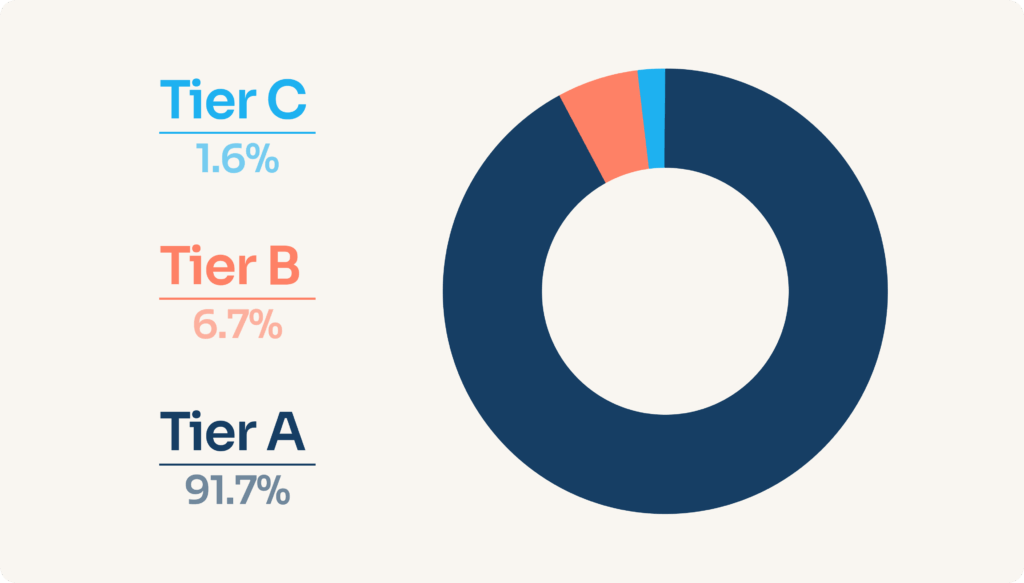
Por eso compartimos públicamente los Tiers y objetivos. Esta lista no es fija. Cada trimestre la revisamos y ajustamos según datos y comentarios. Algunos conectores suben, otros bajan o incluso desaparecen.
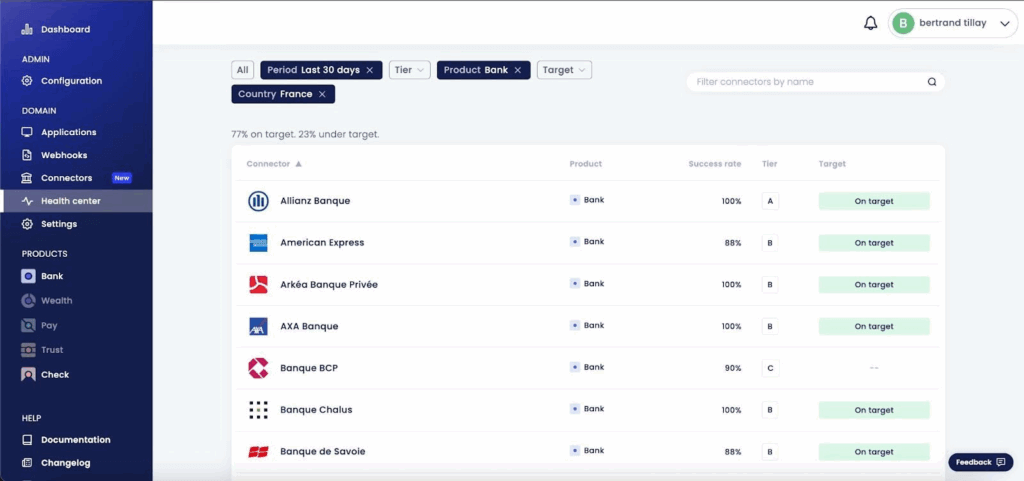
Aceptar que no se puede arreglar todo es fundamental. Hay que tomar decisiones y ser transparentes al respecto. Así es cómo gestionamos las expectativas propias y ajenas.
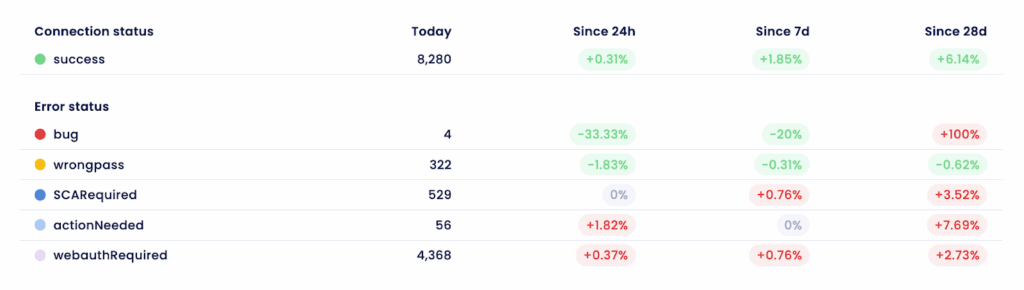
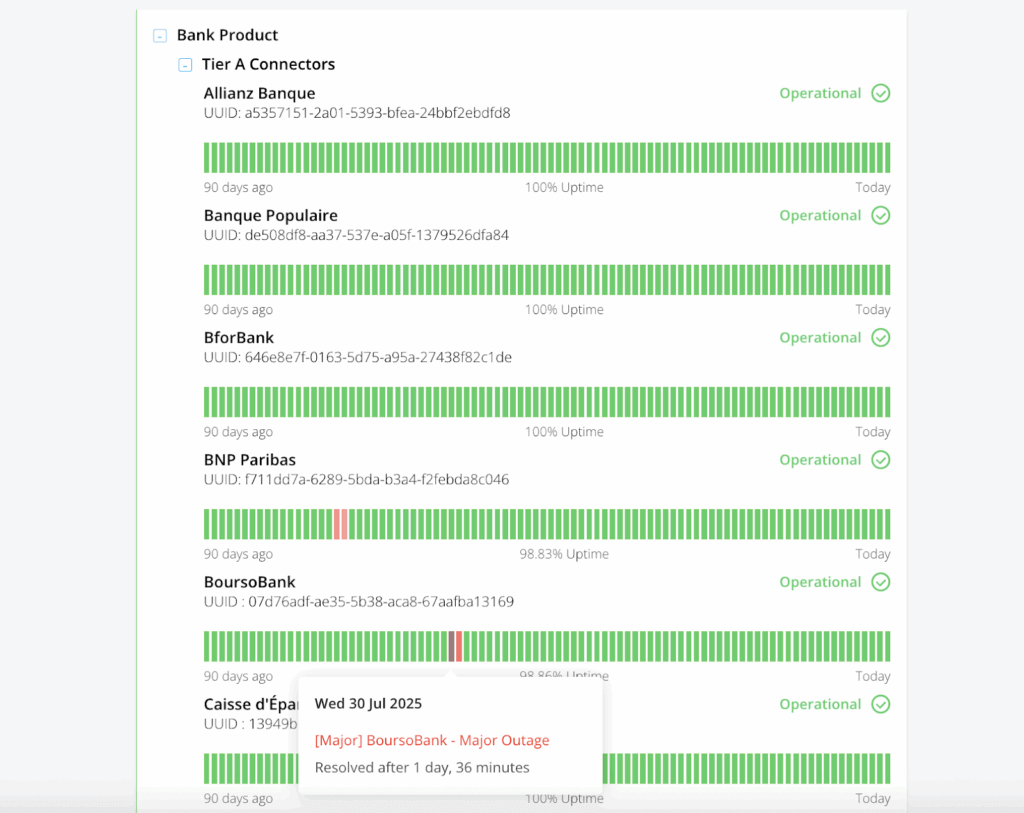
Centrarse en el impacto
Los conectores son una dimensión. Otra es la naturaleza de la anomalía (cualitativa) y su frecuencia (cuantitativa).
Medir por número de ocurrencias es sencillo: cuanto más se repite, más prioritario es. Un error que afecta a 100.000 usuarios importa más que uno que afecta a 1.000.
Evaluar la gravedad cualitativa es más complejo, porque depende del tipo de cliente y del valor que le aporta el servicio. En general, distinguimos tres tipos de anomalía:
- Fallo al añadir una cuenta nueva
- Fallo al actualizar una cuenta existente
- Errores en la calidad de los datos recuperados
Y priorizamos en ese orden: primero los fallos al añadir, luego los de actualización, y por último los problemas de datos.
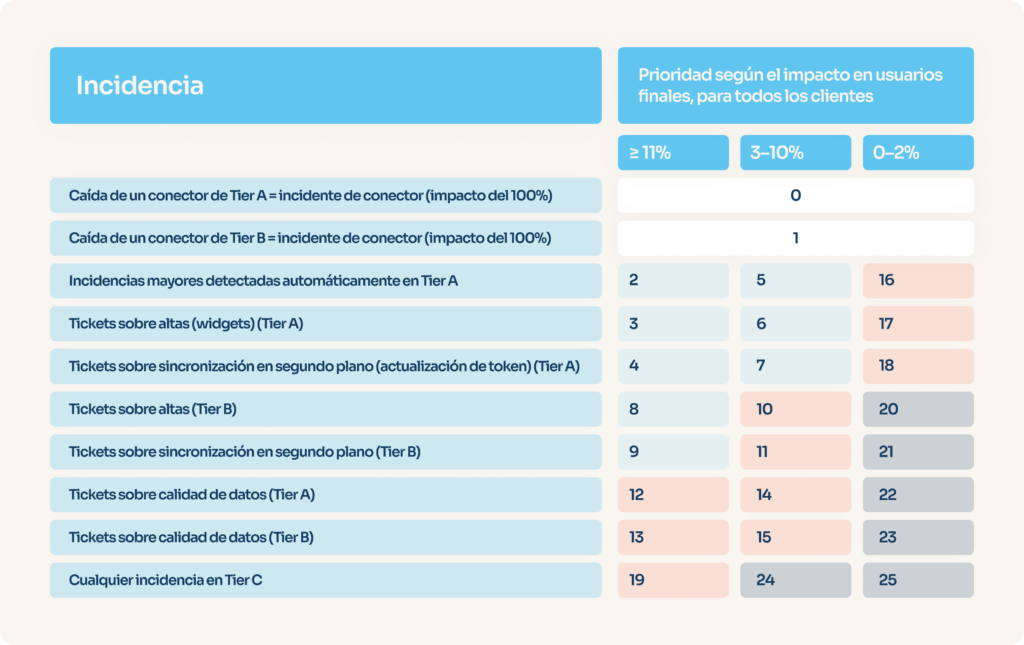
Si combinamos esto con el nivel del conector y su tráfico, hay casos claros: un Tier A que falla al añadir cuentas y representa el 15 % del tráfico es prioridad absoluta.
Pero, ¿y si hay que elegir entre estos dos?
- Un Tier B con fallo total, que representa el 2 % del tráfico
- Un Tier A con fallo parcial (30 %) al actualizar, que equivale al 4 % del tráfico total
Ya no es tan evidente.
Para resolver esto, creamos una matriz de decisión que asigna una prioridad numérica de p0 (máxima) a p25 (mínima), sin duplicados. Nuestra herramienta de monitoreo analiza los logs, calcula la prioridad y luego el equipo puede ajustarla manualmente.
Gestionar el caos
Todo esto está muy bien, pero ¿cómo nos adaptamos a los problemas que surgen de forma impredecible? ¿Y cuándo decidimos no corregir una anomalía de inmediato, sino dejarla para más adelante? Hay meses en los que se nos acumulan varios “p0” a la vez (fallos graves en los conectores), y otros en los que apenas aparece un p2. ¿Cómo equilibramos entonces la corrección de errores con tareas a largo plazo, como mejorar nuestro sistema de supervisión? Si el trabajo de desarrollo se interrumpe constantemente de forma aleatoria, es difícil avanzar, y existe el riesgo de acabar invirtiendo menos de lo necesario en la plataforma, lo que a la larga genera aún más inestabilidad.
Una vez más, necesitamos un sistema que sea lo bastante flexible como para reforzar los recursos tácticamente (por ejemplo, aumentando el número de desarrolladores disponibles para solucionar incidencias), pero también lo bastante firme como para no sacrificar las mejoras estructurales a largo plazo cada vez que haya una urgencia.
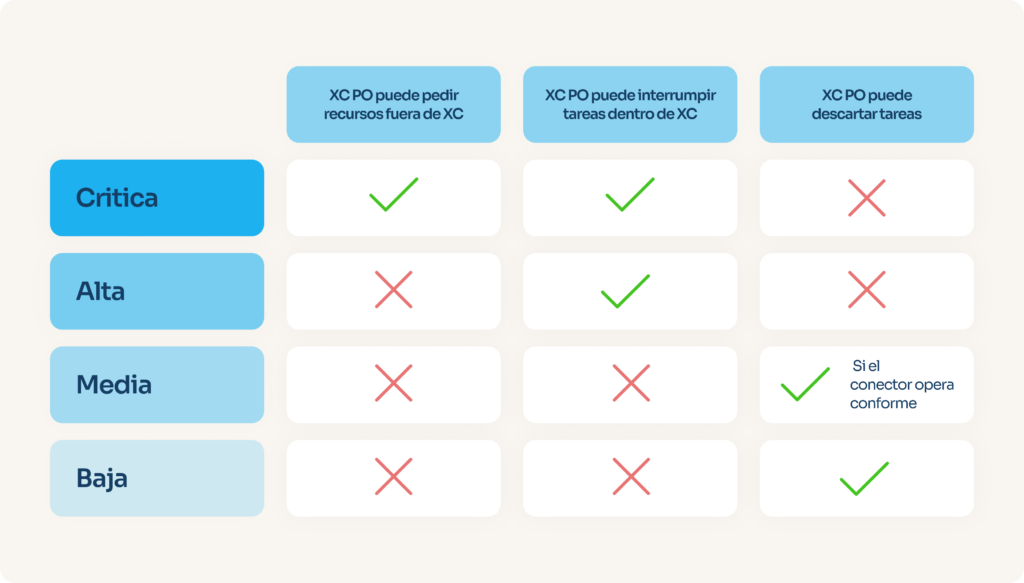
Por eso, decidimos clasificar todas las prioridades en cuatro categorías: crítica, alta, media y baja. Según la categoría, el Product Owner del equipo de conectores tiene más o menos margen de decisión.
Entre sus facultades están: descartar una tarea (decidir no solucionarla nunca), interrumpir cualquier otra tarea en curso —incluidas las estratégicas a largo plazo— o incluso, en los casos más graves, solicitar apoyo inmediato de cualquier desarrollador de la empresa, independientemente del equipo al que pertenezca, hasta que el problema esté resuelto.
Conclusión
La competencia en el sector del Open Banking es intensa, y en Powens Group llevamos tiempo ocupando una posición de liderazgo. Una de las claves ha sido nuestro compromiso con la calidad y la atención al cliente. Para muchos de vosotros, nuestros servicios son esenciales. La tolerancia a las anomalías es baja —y con razón—, por eso asumimos la responsabilidad de ser transparentes y de hacer todo lo posible por estar a la altura de vuestras expectativas.
Nuestro sistema de clasificación y priorización es solo una de las muchas iniciativas que reflejan ese compromiso. Tenemos mucho más que queremos compartir, así que estad atentos.









