People with thin files are often those who need loans the most. Yet, due to the lack of accurate and reliable information available, they are the ones who end up paying higher interest rates or are turned away.
What if lenders could gather information in real-time and have access to much higher quality data? Not only would the applicant get a better rate, but the risk as a lender would be a lot lower and more applications would be approved.
With Open Banking, this is now possible. Lenders can now ask to access a borrower’s financial history via the most reliable source of information: their bank account. By feeding this real-time information into their lending model, lenders can build a much more accurate picture of an applicant and therefore offer a more accessible rate.
Whether a borrower gets approved or not is something that happens in the “decisioning” part of the lending workflow: based on the information the borrower submits, the lender calculates the risk and then makes an informed decision. Although it’s a model that works, we’ll see that there are many flaws with how it’s executed.
This article is the second part of our series on lending where we explain how lenders can use Open Banking to upgrade and improve their lending workflow.
Let’s first look at the problems lenders face when it comes to decisioning.
What problems do lenders face during decisioning

Getting the right data from their clients
Most of the decisioning depends on the information the borrower submits. This means that if the quality of the information is low, lenders need to look elsewhere, or outright reject an applicant.
The problem is that the lending industry still largely relies on outdated and limited financial records, as well as lengthy onboarding and decisioning processes. These outdated processes result in a mismatch between customer and lender: the issue is often the lack of right information, not the lack of information in itself.
This especially rings true during the Covid pandemic. With more people dealing with an unstable income, unemployment and career changes, traditional income verification methods have become more inadequate than ever.
As we mention in part one of our series, most income verification methods currently rely on a snapshot of a borrower’s finances, along with information from credit bureaus (which is often outdated). But a snapshot of a person’s finances will not tell a lender if they’re someone who’s good at paying off debts, whether they impulse buy and whether they save money regularly.
The lack of right information means a lender might accept someone with high income but who has a high debt ratio — and is therefore high risk — but might turn down someone with lower income but a healthier debt ratio.
👉 Learn more: How personal financial data is powering banking innovation
Analyzing that data effectively
Without the right information in the right format, it’s difficult to analyze data effectively and efficiently.
Relying on bank extracts and customer-submitted PDFs rather than real-time information means lenders cannot factor in last-minute circumstances into their analysis. For instance, if a borrower loses their job, not only will a lender often not be aware but inputting that metric into their model could drastically change the loan agreement.
Moreover, instead of relying on income and expenditure, lenders want to be focusing on affordability: the ability of a borrower to pay back a loan based on their habits and financial behavior. Yet, the lack of extensive historical data makes it hard for lenders to gauge this effectively.
Detecting fraudsters
Borrowers manually submit PDFs and bank account information, which means they can be prone to embellishing certain numbers and being selective with the information they provide in order to get a loan approved. There are also bad-faith actors who will outright defraud lenders and tamper with applicant information.
Throughout 2020, the British Business Bank estimated losses of up to £26 billion due to fraud and credit risk: applicants who were not fully transparent with their personal finances.
👉 Read more: Online fraud: Facing it with APIs
Making the right decisions
Considering the fact that it’s hard to get the right data from customers, the tools aren’t in place to measure the right metrics and information is at risk of being fraudulent, it’s no wonder that making the right decisions is one of the largest problems lenders face.
Incorrect decisions increase the risk of the lender’s loan book and lead to larger losses down the road. It also makes lenders a lot more risk-averse and therefore unable to offer loans to those who need them most.
So how can lenders use better technologies to improve their decisioning process? Let’s compare the traditional workflow with the Open Banking-enabled approach.
The decisioning workflow with and without Open Banking
The traditional way
In part one, we explain the traditional onboarding process in detail. The traditional decisioning process is not too different.
How does it work? The borrower inputs tedious amounts of financial information during the onboarding process via an extensive online form. This is then supported with, usually, 3 months of bank statements, address information, and account balances, all through PDFs and spreadsheets. Once the lender receives the information, they might go to a credit bureau to gather more information on the applicant.
Data is then input into the lender’s decisioning model to determine the risk of the borrower, whether to approve them or not and what interest the borrower should pay. Since the sources of information are often outdated or inaccurate, by their nature, the models are inaccurate as well.
Once the lender makes a decision, they communicate it to the borrower. Depending on the situation, this whole process can take several days. This creates a poor experience for the borrower because it involves drawn out uncertainty and many requests for credit are urgent.
With Open Banking
Open Banking drastically increases the quality of the data the lender uses to make decisions. Instead of relying on customer-submitted data, the entire decision process is informed by bank data, which is obtained in real-time and from a reliable source: the borrower’s bank.
The source of data accurately reflects the customer’s financial situation, and the lender can choose which financial information to view (all with the borrower’s consent).
Capturing data in real-time allows lenders to use more advanced tools such as data categorization and advanced financial indicators which offer much deeper insights into a customer’s financial health. Thanks to these tools (more on these below) lenders can keep track of specific metrics of interest — such as how long it takes for a person to repay their debts, how often their account is overdrafted, or their net cashflow — allowing them to truly measure the risk of a borrower.
Accessing a customer’s financial data directly gives lenders a much more holistic view of the borrower, enabling them to make more informed and higher-quality decisions. Instead of manually reviewing and inputting data, lenders can integrate it directly and review an applicant’s financial history in minutes, allowing them to process and respond to requests practically in real time.
👉 Read more: 7 Ways Open Banking can improve customer experience
With Open Banking, lenders can focus on the metrics that matter, and open up their loan book to nontraditional borrowers.
The decisioning process looks like this:
1. After onboarding, the lender now has direct access (read-only) to the borrower’s financial records and can monitor them in real-time.
2. The lender can use this information with varying degrees of depth (using raw aggregation data, categorized data as well as financial indicators) to feed their lending model and measure the affordability of the applicant.
3. The lender doesn’t need to process anything manually and doesn’t even need to turn to credit bureaus for more information. Everything is kept in-house.
4. The process can take under 5 minutes, and the response is immediately sent to the borrower
5. Once the borrower is approved, the loan is issued and the lender can continue to monitor the borrower’s accounts in real-time with continuous access through Open Banking.
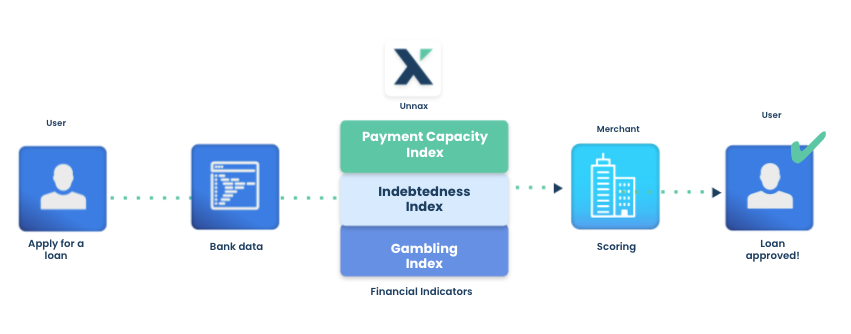
Bank data is hands-down the most transparent, reliable, and easy data source for lenders to base their credit decisions on. High-quality data translates into accurate credit decisions, and therefore lower risk.
👉 You may like: How Open Banking Lets Retail Banks Quickly Add Value for their Customers
What are the technologies that enable better decisions?
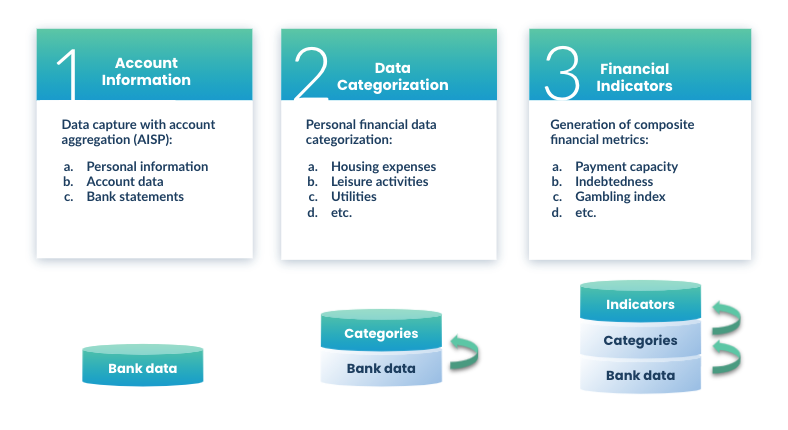
Aggregation
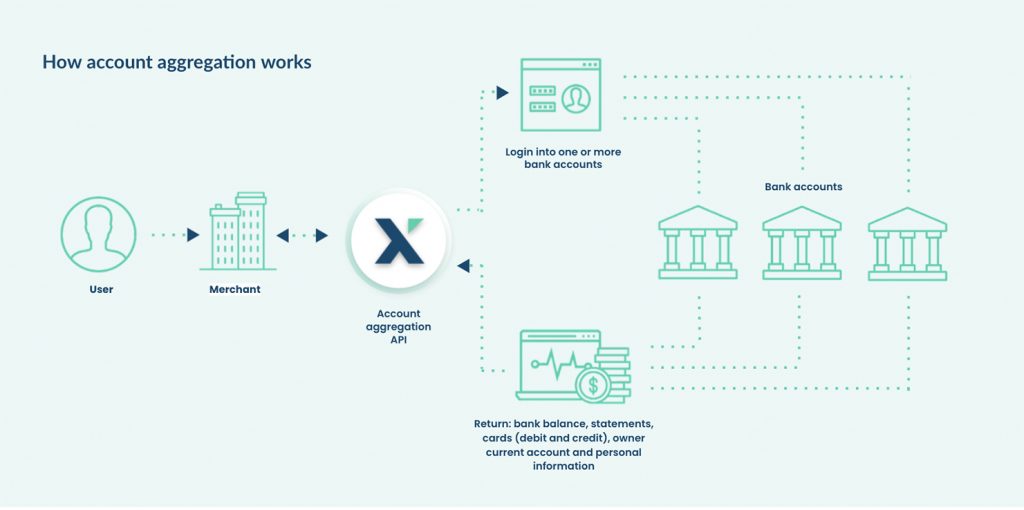
Aggregation is a technology that enables lenders to connect to several financial accounts of a loan applicant and feed them all through one API. With aggregation, the lender can integrate into a borrower’s checking account, savings account, and loan account and view all the relevant information on one dashboard.
Based on this information, lenders can learn about consumers’ financial habits across various accounts, rather than just their checking accounts. For example, an aggregated savings and checking account might show that the applicant saves 10% of their income every month and puts it in their savings. With this information, lenders can understand a borrower’s habits and make them part of the credit decision.
This is especially useful for self-employed, freelancers, and gig workers who have unstable incomes. Combining several accounts and seeing them holistically will allow lenders to issue more loans to more people while keeping the risk low.
👉 Read more: Everything you need to know about Account Aggregation
Categorization
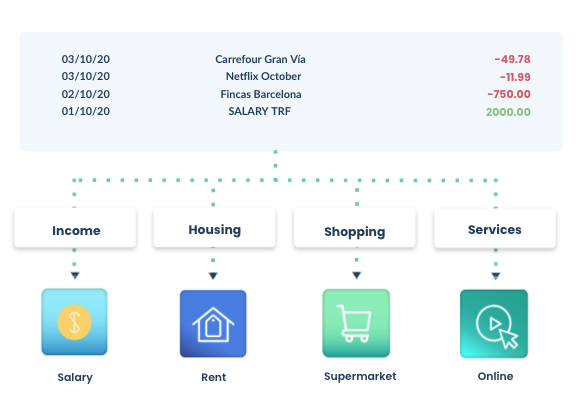
Categorization is the process of labeling and classifying financial transactions through a specific category. That means that transactional data can be translated relatively quickly, making it easy to break down income and expenses separately.
With categorization, lenders can calculate the affordability of a borrower in a few minutes.
Indicators
Indicators are premade formulas that go hand in hand with categorization. They are essentially metrics that effectively illustrate an applicant’s financial health and behavior. Some examples of indicators are a customer’s debt ratio, what percentage of their salary they spend on expenses, and how many days it takes them to pay off an overdraft.
These highly specific metrics are designed to communicate a customer’s payment capacity, and therefore enable lenders to make better decisions and lower risk.
It’s important to note that categorization and financial indicators are not inherently part of Open Banking, and are tools that are usually implemented by an Open Banking provider.
👉 Find out more: Financial Indicators: everything you need to know
When the data sources are inaccurate and the processes are manual and time-consuming, lenders are prone to making errors, falling victims to fraud, and issuing loans to high-risk borrowers.
With Open Banking, decisioning becomes a lot less risky, faster, and more efficient. For lenders, this translates into a lower risk loan book and the capacity to offer loans to a larger pool of applicants. And for borrowers, it means access to lower rates and a much more accurate loan agreement, no matter how thin their profile is.








